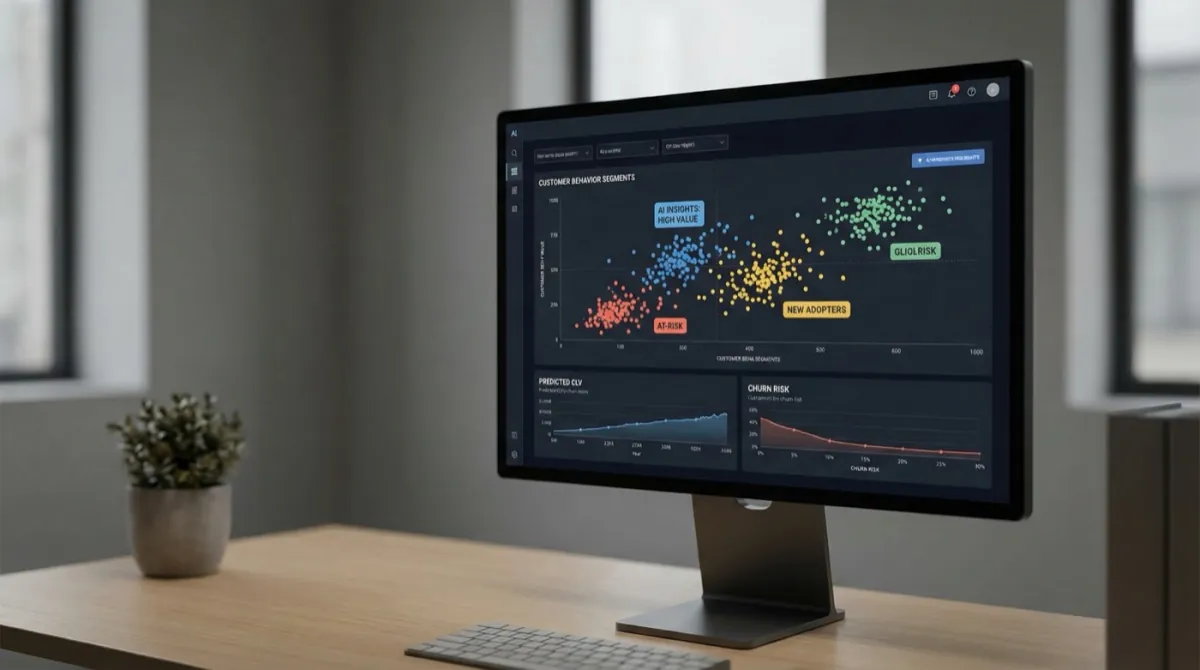
- The model is the easy 10%. Reproducibility, data pipelines, deployment, monitoring and ownership are the 90% that decides whether anything ever ships.
- Gartner has reported for years that roughly half of ML models never reach production. The blocker is almost never the algorithm.
- Training/serving skew is the silent killer: the same feature computed two different ways in two different codebases quietly degrades accuracy with no error in the logs.
- Do not buy a heavyweight MLOps platform for two models. Match tooling to model count and update frequency, and add a feature store only when skew actually bites.
Your data scientists built a model that hits 94% on the validation set. Eight months later it is still running in a notebook on someone's laptop. This is the normal outcome, not the exception, and MLOps is the discipline that exists specifically to fix it.
The model is the easy part
Gartner has reported for years that something close to half of all machine learning models never reach production. The exact number moves with who is counting, but the direction never changes: most enterprise ML dies before it ships.
When that happens, the instinct is to blame the model. Wrong features, wrong algorithm, not enough data. In practice the model is rarely the problem. A competent data scientist with clean data gets a usable model in weeks. The model is maybe 10% of the work.
The other 90% is everything around it: getting the same data to the model in production that it saw in training, deploying it without a six-week change cycle, knowing when it starts to fail, and having a named human responsible for it. That 90% is what MLOps is. Skip it and you get a brilliant prototype no one can run.
A notebook is a great place to explore and a terrible place to run a business process: stateful, cells run out of order, paths hardcoded, half the logic in the data scientist's head. The gap shows up the moment someone asks whether you can run it again next month and get the same behaviour. The honest answer is usually no. Closing it means turning the notebook into a pipeline: parameterised, runnable from a command, explicit inputs and outputs, no hidden state. Packaging the model as a reproducible ML pipeline rather than a script removes more friction than any platform purchase.
Versioning is three things, not one
Software teams version code and think they are done. For machine learning in production you have to version three things together, or you reproduce nothing:
- Code. The training and inference logic. Git already does this well.
- Data. The exact training set. A model is a function of its data, so "which data" is part of the artifact. DVC, lakeFS, or immutable dated snapshots in object storage do the job.
- Model. The trained weights plus the metadata that produced them: hyperparameters, training set version, metrics, library versions.
The test is simple. A regulator, an auditor, or your own incident review asks: which exact model made this prediction last March, and on what data was it trained. If you cannot answer in minutes, you do not have versioning, you have hope. In regulated European sectors this is not optional, and the EU AI Act tightens it.
CI/CD for models is not CI/CD for code
Borrow the discipline, but do not assume it transfers unchanged. A code deploy is deterministic: same input, same output. A model deploy is not, because its behaviour depends on data it has never seen.
So CI/CD for models needs extra gates classic pipelines lack:
- Automated retraining triggered by code, data, or schedule, not by a human remembering.
- Validation that checks model quality, not just that the tests pass. A model can pass every test and still be worse than the one in production.
- A champion/challenger step: the new model has to beat the incumbent on held-out data before promotion.
- A fast, boring rollback, the same one-command revert you would use on a bad code release.
"The build is green" tells you nothing about whether the new model is actually better. That has to be tested explicitly.
Training/serving skew, the silent killer
Here is the failure that quietly destroys more deployed models than any other, and it produces no error in the logs.
In training, a feature like "average order value over the last 30 days" is computed in a tidy pandas script over a historical table. In production, the same feature is computed live, often in a different language, by a different team, against a streaming source. The two implementations drift apart. Maybe production counts refunds and training did not. The model now sees slightly different numbers than it learned from. Nothing crashes. Accuracy just bleeds out. This is training/serving skew, the main reason a 94% notebook model becomes a mediocre production one.
The clean fix is a feature store: compute each feature once, then serve the identical value to both training and inference. That is genuinely what feature stores are for. But be honest about cost: a feature store is real infrastructure. With two models and ten features, a single shared feature library in code gets you most of the benefit. Reach for the feature store when reuse across many models, or measurable skew, justifies it. Not before.
Monitoring: the model that fails without telling you
Traditional monitoring watches whether the service is up. ML monitoring has to watch something harder: whether the model is still right. A model can be up, fast, and returning 200s while being completely wrong. Two distinct things shift:
- Data drift. The input distribution moves: new customer mix, a pricing change, a new product line. The world the model was trained on no longer exists.
- Model drift / concept drift. The relationship between inputs and what you predict changes. Fraud patterns evolve to beat your detector. Buying behaviour shifts after a shock.
The dangerous case is silent degradation: no alert, no outage, just predictions getting slowly worse while everyone assumes the model is fine because it shipped a year ago. Model monitoring for drift turns that into an alert you act on, instead of a discovery made after the business notices the numbers are off. At minimum, track input and prediction distributions over time, and where you can, close the loop on outcomes to measure live accuracy.
Who owns the model at 3am
This is the question that kills more ML programs than any technical gap, and it is organisational.
A data scientist builds the model and moves on. It is now running in production, making real decisions. Six months later it starts drifting. Who notices. Who is paged. Who is allowed to retrain and redeploy it. In most enterprises the answer is nobody, and the model rots until someone downstream complains.
A model in production is a living system, not a delivered artifact. It needs an owner the way a service does: a named team accountable for its health, with the access and mandate to fix it. If you cannot name that team before you deploy, you are not ready to deploy.
A realistic maturity path
Do not boil the ocean. The fastest way to get nothing into production is to spend a year standing up a platform before shipping one model. Match the investment to where you are:
- Level 0, one or two models, rare updates. Reproducibility and versioning, a runnable pipeline, a clean manual deploy with rollback, basic input and prediction monitoring. No platform needed.
- Level 1, several models, regular retraining. Automate the pipeline. Add a model registry, a validation gate, drift monitoring with alerts, and explicit ownership.
- Level 2, many models, frequent updates, heavy feature reuse. Now a feature store and a full CI/CD-for-models platform earn their cost.
Most enterprises are at Level 0 and try to buy Level 2. That is how you end up with an expensive platform and still nothing in production. Buy the platform when the model count forces your hand, not because a vendor deck did.
How DNA helps
We ship machine learning into production in regulated European enterprises, where reproducibility, monitoring, and ownership are what stand between a prototype and a system the business trusts. We start by finding why your models are not shipping (usually the pipeline and the org chart, not the algorithm), then build the MLOps practice that fits your maturity, not a vendor's. If you have models stuck in notebooks, let's talk about getting them to production.
Related services: AI & Machine Learning, Data & Analytics, Cloud Solutions
Industry: Retail & Distribution