Führende europäische Organisationen vertrauen uns







Dashboards und Proof of Concepts sind schnell gebaut; Systeme, die dem Tagesgeschäft standhalten, nicht. DNA Solutions migriert Infrastruktur in die Cloud, konsolidiert Daten in Plattformen, die Teams im Tagesgeschäft nutzen, und bringt KI in den Produktivbetrieb, zu europäischen Bedingungen.
Führende europäische Organisationen vertrauen uns
Cloud, Daten und KI scheitern, wenn sie als getrennte Projekte eingekauft werden. DNA Solutions baut sie als einen Stack: Die Migration bereitet die Datenplattform vor, die Datenplattform speist die Modelle, und jede Ebene bleibt auf Infrastruktur, die Sie kontrollieren.
Legacy-Systeme belasten Budgets mit steigenden Lizenzkosten und begrenzter Skalierbarkeit. Unsere Cloud-Migration auf AWS und Azure modernisiert Unternehmensinfrastruktur, ohne das Tagesgeschäft zu unterbrechen.
Zur Leistung →Wir führen Ihre verstreuten Datenquellen in einheitlichen Analyseplattformen zusammen, mit denen Entscheider arbeiten: Echtzeit-Dashboards, Self-Service-BI und prädiktive Auswertungen.
Zur Leistung →Wir setzen Machine-Learning-Modelle auf Ihre Unternehmensdaten an, um Wartungsfenster, Kundenabwanderung und Umsatztrends zu prognostizieren. Unsere Pipelines laufen auf Ihren bestehenden Datenplattformen.
Zur Leistung →Wir integrieren KI und Machine Learning in Ihre bestehende Unternehmensinfrastruktur, um Prozesse zu automatisieren, Ergebnisse zu prognostizieren und Abläufe zu optimieren, von intelligenter Dokumentenverarbeitung bis zur Bedarfsprognose.
Zur Leistung →Dokumentenautomatisierung mit eigenen KI-Modellen auf europäischer Infrastruktur, ohne Abhängigkeit von OpenAI oder Hyperscalern. Unsere Klassifikationsmodelle übertrafen Azure AI auf 2 von 3 Benchmark-Datensätzen (94,7 % vs. 84,2 % auf Canon-Dokumenten), DSGVO- und AI-Act-ready.
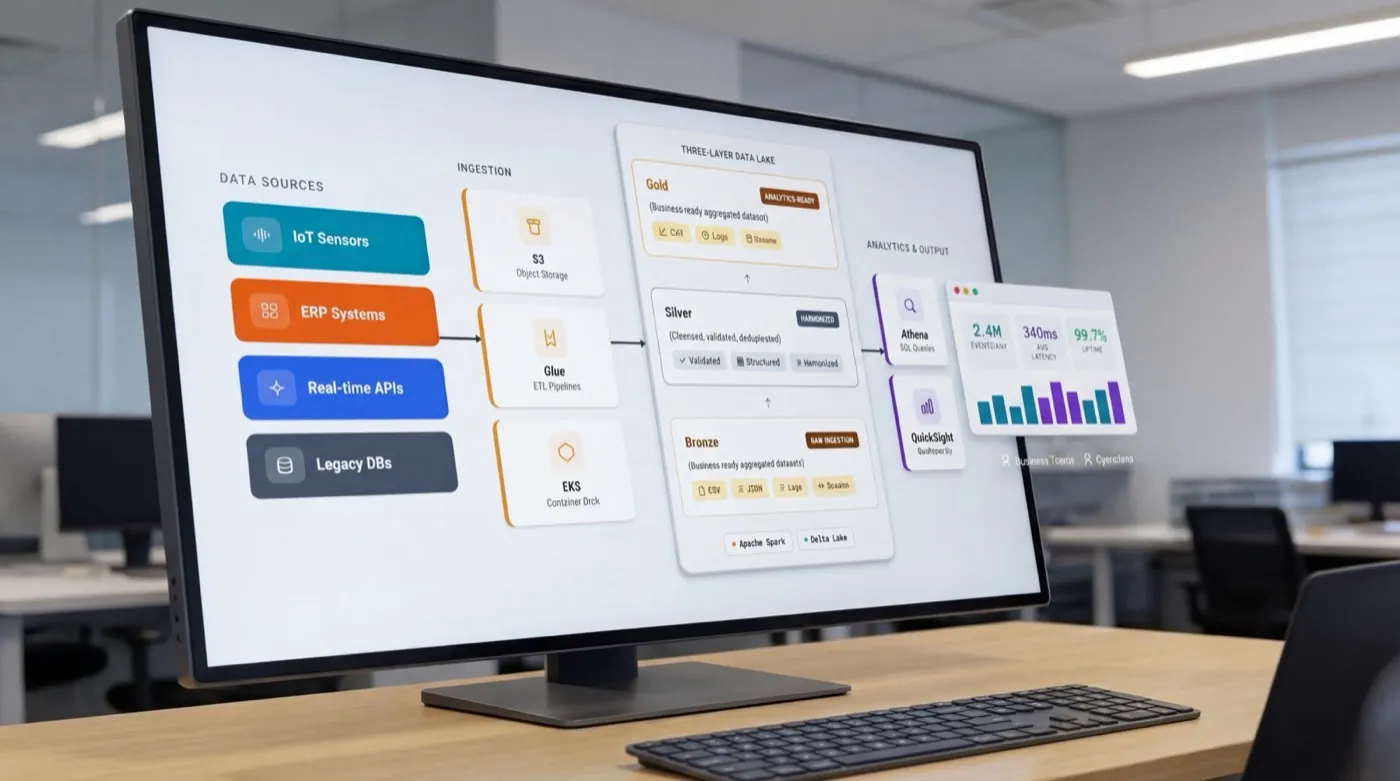
Zur Leistung →Diese fünf Leistungen sind Stufen eines Stacks, kein Menü unverbundener Optionen. Die Cloud-Migration schafft die elastische, lizenzfreie Infrastruktur, die eine Datenplattform braucht. Die Datenplattform konsolidiert verstreute operative Quellen in einer einzigen, kontrollierten Schicht. Analysen und Prognosemodelle greifen auf diese Schicht zu, und die KI sitzt obenauf, trainiert auf Daten, die bereits bereinigt, dokumentiert und rechtlich geklärt sind. Sie können auf jeder Stufe einsteigen, aber jedes Projekt ist so angelegt, dass die nächste Ebene auf etwas Solidem aufsetzt.
Europäische Infrastruktur zuerst: Cloud-, Daten- und KI-Workloads laufen in europäischen AWS- und Azure-Regionen oder auf souveränem Hosting, je nachdem, was Ihre Daten rechtlich dürfen. Portabilität bauen wir vom ersten Tag an mit: Infrastruktur als Code, Open Source, wo es passt, und Architekturen, die Ihre Ingenieure selbst betreiben.
Souveränität ist bei uns Engineering-Anforderung, nicht Compliance-Übung: Datenresidenz, DSGVO und AI Act prägen das Design vor dem ersten Deployment.

Wir entwickeln Technologie mit messbarem Beitrag zu Ihrem Geschäftsergebnis. Europäische Unternehmen vertrauen uns extreme Datenvolumen und kritische Finanz-Pipelines an.
Kundenergebnisse ansehenDurch die Optimierung von Softwarelizenzkosten haben wir für mehrere europäische Organisationen über 1 Mio. € an jährlichen Einsparungen realisiert.
Wir haben eine von Deloitte geprüfte Billing-Plattform gebaut und betreiben sie bis heute: 300 Mio. € an geprüften Transaktionen, jeden Monat.
Ein Senior-Team aus Ingenieuren und Consultants, verteilt über Europa.
T-Systems, Satellic, Europäische Kommission: Unsere längsten Engagements halten, weil wir liefern.

Die meisten Kunden kommen mit einem dringenden Projekt und entdecken den Rest des Wegs später. Das ist die Abfolge, die wir bei europäischen Unternehmen am häufigsten sehen: was jede Stufe für sich liefert und was sie an die nächste übergibt.
Ausgangspunkt ist meist ein Legacy-Bestand, oft Oracle oder SAP, teuer in der Lizenz und schwer zu skalieren. Wir re-platformen ihn in Phasen: Jeder Workload wird vor dem Cutover gegen das Altsystem validiert, Change Data Capture hält beide Seiten synchron. Was diese Stufe an die nächste übergibt: elastische Infrastruktur, niedrigere Betriebskosten und Daten, die endlich erreichbar sind.
Steht die Infrastruktur, konsolidieren wir operative Quellen in einem kontrollierten Data Lake oder Warehouse. Für einen europäischen Mautbetreiber hieß das, mehr als 90 Quellen aus Oracle, PostgreSQL und MongoDB in einer einzigen Echtzeit-Schicht zu vereinen. Qualitätsregeln, Lineage und Zugriffskontrollen werden hier definiert, denn alles, was später entsteht, erbt sie.
Mit einer kontrollierten Datenschicht wandert das Reporting von manuellen Exporten zu Echtzeit-Dashboards und Self-Service-BI. Der Maßstab für Erfolg ist hier die Nutzung: Führungskräfte und Fachteams beantworten ihre Fragen selbst aus der Plattform, statt Auswertungen anzufordern. Abfragen, die früher Tage dauerten, kommen in Stunden oder weniger zurück.
Prognosen werden erst verlässlich, wenn die Plattform darunter stabil ist. Wir bauen Machine-Learning-Pipelines für die Vorhersagen, die operative Entscheidungen tragen: Wartungsfenster, Kundenabwanderung, Nachfrage- und Umsatztrends. Die Modelle laufen auf derselben kontrollierten Datenschicht, Retraining und Monitoring gehören damit zum Regelbetrieb statt zu einem separaten Forschungsprojekt.
Die letzte Stufe ist KI im täglichen Einsatz: intelligente Dokumentenverarbeitung, Matching-Engines, eigene Modelle, trainiert auf Ihren Daten. Wo Souveränität zählt, bauen wir ohne Hyperscaler-KI-Abhängigkeiten; unsere Modelle zur Dokumentenklassifikation übertrafen Azure AI auf 2 von 3 Benchmark-Datensätzen, darunter 94,7 % gegenüber 84,2 % auf Canon-Dokumenten. Jedes Modell wird mit Monitoring und Retraining-Plan ausgeliefert.
Cloud- und Analyseplattformen im täglichen Einsatz bei europäischen Unternehmen.
Ein europäischer Transportbetreiber brauchte für Analysen über fragmentierte Datenbanken Tage, mit hartem Oracle-Lock-in. Wir haben einen cloud-nativen Data Lake auf AWS aufgebaut.
Abfragezeiten: von Tagen zu Stunden
Ein großer Mautbetreiber musste über 90 fragmentierte Quellen aus Oracle, PostgreSQL und MongoDB vereinen. DataPulse machte aus diesem Bestand eine einzige Echtzeit-Analyseschicht.
90+ Datenquellen vereintSenior-Entscheider über die Plattformen und Infrastrukturen, die wir geliefert haben.
"DNA works with us to deliver digital systems at scale so that we can serve our customers digitally. They are both reactive to requests and proactive with ideas and proposals."
"I appreciated the collaborative spirit and the effort to deliver a reliable solution within a reasonable budget. The step-by-step approach with a demo before deployment made all the difference."
"The quality of the people I worked with and the seriousness of the project management stood out. DNA built a backend and app for a highway toll system, and the human side of the company is truly remarkable."
Was CIOs und Datenverantwortliche geklärt haben wollen, bevor sie sich auf einen mehrjährigen Stack festlegen: Reihenfolge, Anbieterwahl, Zeitrahmen und Regulierung. Das sind die Antworten, die wir im Erstgespräch geben.
Nein, und auf die perfekte Plattform zu warten ist meist ein Fehler. Die Reihenfolge zählt, weil produktive KI kontrollierte, erreichbare Daten braucht, aber beide Stränge können parallel laufen: ein begrenzter KI-Pilot auf einem gut verstandenen Datensatz, während die breitere Migration voranschreitet. DNA Solutions führt oft beides gleichzeitig, wobei der Pilot so zugeschnitten ist, dass seine Datenquellen zu den ersten migrierten Workloads gehören. Wovon wir abraten: KI organisationsweit auf einem fragmentierten Legacy-Bestand auszurollen, weil jedes Modell dann die Datenqualitätsprobleme darunter erbt. Starten Sie den Piloten früh, aber lassen Sie die Plattform aufholen, bevor Sie in die Breite gehen.
Die Wahl folgt drei Fragen: Wo dürfen Ihre Daten rechtlich liegen, was verlangt das Workload-Profil tatsächlich, und welches Tooling betreiben Ihre Teams bereits. Europäische AWS- und Azure-Regionen decken die meisten Enterprise-Fälle ab; zwischen beiden entscheiden wir nach Workload-Eignung, nicht nach Vorliebe. Souveränes europäisches Hosting wird zur richtigen Antwort, wenn Anforderungen der öffentlichen Hand, Branchenregulierung oder strategische Unabhängigkeit eine Hyperscaler-Abhängigkeit ausschließen, besonders bei KI-Workloads mit sensiblen Dokumenten. Weil wir auf Portabilität hin bauen, mit Infrastructure as Code und offenen Standards, bleibt die Entscheidung später revidierbar statt eine Einbahnstraße.
Ein erster produktiver Use Case steht typischerweise nach drei bis sechs Monaten: ein begrenztes Set an Quellen konsolidiert, Qualitätsregeln etabliert, und ein Team, das echte Fragen aus der Plattform beantwortet. Die vollständige Konsolidierung dauert länger und hängt vor allem von Zahl und Zustand Ihrer Quellen ab; ein Bestand von über 90 Datenbanken braucht mehr als ein Jahr, bis er vollständig integriert ist. Wir phasen die Arbeit bewusst so, dass der Nutzen früh ankommt, denn ein Data Lake, der 18 Monate unsichtbar bleibt, verliert seine Sponsoren, bevor er sein Budget verliert. Jede Phase fügt Quellen zu einer Plattform hinzu, die bereits täglich genutzt wird, statt auf einen einzigen fernen Launch hinzuarbeiten.
Als Designvorgaben, geklärt vor dem ersten Deployment statt im Nachhinein geprüft. Für die DSGVO heißt das: Datenresidenz in europäischen Regionen oder auf souveränem Hosting, Datenminimierung direkt in den Pipelines, Zugriffskontrollen und Audit-Trails auf Plattformebene sowie Unterstützung Ihrer Datenschutz-Folgenabschätzung. Für den AI Act heißt es: jeden Use Case nach Risikokategorie einordnen, Modelle und Trainingsdaten so dokumentieren, dass sie einer Prüfung standhalten, und den Menschen dort in der Schleife halten, wo die Verordnung es verlangt. Wo die Anforderungen Hyperscaler-KI-Dienste ganz ausschließen, trainieren und betreiben wir eigene Modelle auf europäischer Infrastruktur, ohne externe API-Abhängigkeit.
Das ist der Normalfall, und die Übergabe wird von Anfang an geplant statt am Ende improvisiert. Ihre Ingenieure arbeiten im Projekt mit, die Infrastruktur wird als Code verwaltet, sodass jede Umgebung reproduzierbar ist, und die Architektur ist durchgängig dokumentiert. Wenn die Plattform stabil läuft, betreibt Ihr Team sie im Alltag, und wir bleiben dort eingebunden, wo es Sinn ergibt: neue Stufen des Stacks, Modell-Retraining oder Kapazität, die Ihr Team nicht intern aufbauen muss. Die Abhängigkeit, die Sie behalten, soll eine Entscheidung sein, nie eine Folge davon, wie das System gebaut wurde.