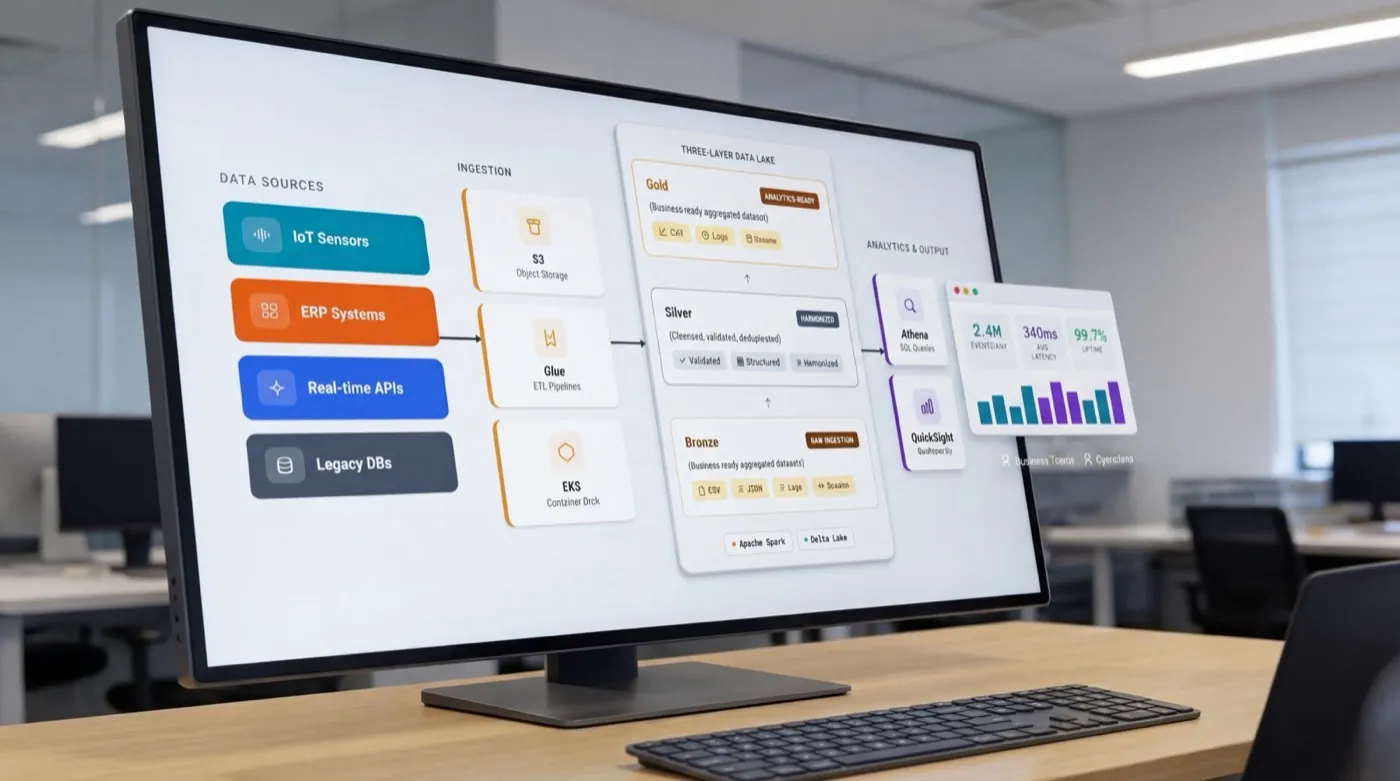
Was DNA Solutions im Data Engineering auszeichnet
Wir bauen zentrale Datenplattformen, die fragmentierte Quellen in einer Abfrageumgebung konsolidieren, Vendor-Lock-in beenden und Teams Echtzeitzugriff auf Produktionsdaten geben. Unsere Ingenieure migrieren Oracle- und SAP-Workloads auf cloud-native Data Lakes und setzen darauf Warehousing auf PostgreSQL, Snowflake und Redshift, Streaming-Pipelines, Self-Service-Analytics und Predictive Analytics auf. Unser Senior-Team bringt über 15 Jahre Erfahrung mit Enterprise-Dateninfrastruktur mit.