Trusted by Europe's leading organizations







Dashboards and proofs of concept are easy; systems that hold up in daily operations are not. DNA Solutions migrates infrastructure to the cloud, consolidates data into platforms teams actually use, and ships AI that runs in production on European terms.
Trusted by Europe's leading organizations
Cloud, data and AI fail when they are bought as separate projects. DNA Solutions builds them as one stack: the migration prepares the data platform, the data platform feeds the models, and every layer stays on infrastructure you control.
Legacy systems drain budgets with rising licensing costs and limited scalability. Our AWS and Azure cloud migration services modernize enterprise infrastructure without disrupting daily operations.
Explore service →We consolidate your scattered data sources into unified analytics platforms that executives actually use: real-time dashboards, self-service BI, and predictive insights.
Explore service →We apply machine learning models to your enterprise data to forecast maintenance windows, customer churn, and revenue trends. Our pipelines run on top of your existing data platforms.
Explore service →We integrate AI and machine learning into your existing enterprise infrastructure to automate processes, predict outcomes, and optimize operations, from intelligent document processing to demand forecasting.
Explore service →Custom AI built on European infrastructure with no OpenAI or hyperscaler dependency. Our document classification models outperformed Azure AI on 2 of 3 benchmark datasets (94.7% vs 84.2% on Canon), GDPR and AI Act ready.
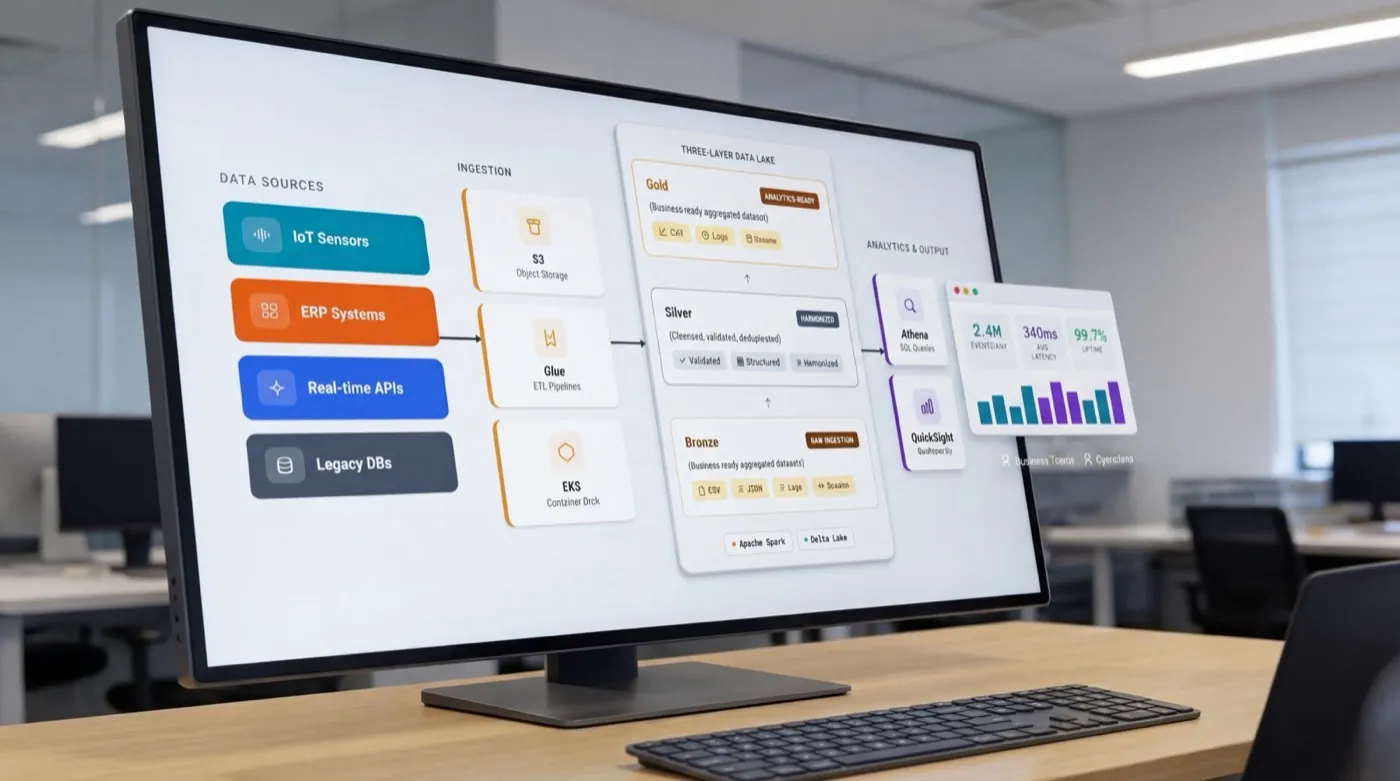
Explore service →These five services are stages of one stack rather than a menu of unrelated options. The cloud migration creates the elastic, license-free infrastructure a data platform needs. The data platform consolidates scattered operational sources into a single governed layer. Analytics and predictive models draw on that layer, and AI sits on top, trained on data that is already clean, documented and legally settled. You can enter at any stage, but every engagement is built so the next layer has something solid to stand on.
European infrastructure first: workloads run in AWS and Azure European regions or on sovereign European hosting, depending on what your data is legally allowed to do. Portability is engineered into every enterprise technology stack, with infrastructure as code your engineers can operate after handover.
Sovereignty is an engineering constraint, not an afterthought: data residency, GDPR and the AI Act shape the design before deployment, and every project is scoped past the proof of concept.

We design technology that lands on your bottom line. European enterprises trust us with extreme data volumes and critical financial pipelines.
See Client ResultsBy optimizing software licensing fees for several European organizations, we delivered over €1M in annual cost savings.
We built and maintain a Deloitte-audited billing platform processing €300M in audited transactions every month.
A senior team of engineers and consultants across Europe.
T-Systems, Satellic, European Commission: our longest engagements last because we deliver.

Most clients arrive with one urgent project and discover the rest of the path later. This is the sequence we see most often across European enterprises, what each stage delivers on its own, and what it hands to the next one.
The starting point is usually a legacy estate, often Oracle or SAP, that is expensive to license and hard to scale. We re-platform it in phases, with each workload validated against the legacy system before cutover and Change Data Capture keeping both sides synchronized. What this stage hands to the next: elastic infrastructure, a lower run cost, and data that is finally reachable.
Once the infrastructure is in place, we consolidate operational sources into a governed data lake or warehouse. For one European toll operator this meant unifying more than 90 sources spread across Oracle, PostgreSQL and MongoDB into a single real-time layer. Quality rules, lineage and access controls are defined here, because everything built later inherits them.
With one governed layer in place, reporting moves from manual extracts to real-time dashboards and self-service BI. The measure of success at this stage is adoption: executives and operational teams answering their own questions from the platform instead of requesting exports. Queries that previously took days come back in hours or less.
Forecasting only becomes reliable once the platform beneath it is stable. We build machine learning pipelines for the predictions that drive operational decisions: maintenance windows, customer churn, demand and revenue trends. The models run on the same governed data layer, so retraining and monitoring are part of normal operations rather than a separate science project.
The final stage is AI embedded in daily operations: intelligent document processing, matching engines, custom models trained on your own data. Where sovereignty matters, we build without hyperscaler AI dependencies; our document classification models outperformed Azure AI on 2 of 3 benchmark datasets, including 94.7% versus 84.2% on Canon documents. Every model ships with monitoring and a retraining plan.
Cloud and analytics platforms in daily use at European enterprises.
A European transportation operator ran analytics that took days across fragmented databases, with hard Oracle lock-in. We architected a cloud-native data lake on AWS.
Query latency: days → hours
A major toll operator needed to unify 90+ fragmented data sources locked across Oracle, PostgreSQL and MongoDB. DataPulse turned that estate into a single, real-time analytics layer.
90+ data sources unifiedSenior decision-makers on the platforms and infrastructure we have delivered.
"DNA works with us to deliver digital systems at scale so that we can serve our customers digitally. They are both reactive to requests and proactive with ideas and proposals."
"I appreciated the collaborative spirit and the effort to deliver a reliable solution within a reasonable budget. The step-by-step approach with a demo before deployment made all the difference."
"The quality of the people I worked with and the seriousness of the project management stood out. DNA built a backend and app for a highway toll system, and the human side of the company is truly remarkable."
What CIOs and data leaders want settled before committing to a multi-year stack: sequencing, provider choice, timelines and regulation. These are the answers we give on a first call.
No, and waiting for a perfect platform is usually a mistake. The sequence matters because production AI needs governed, reachable data, but the two threads can run in parallel: a bounded AI pilot on one well-understood dataset while the broader migration progresses. DNA Solutions often runs both at once, with the pilot scoped so its data sources are among the first workloads migrated. What we advise against is scaling AI across the organization on top of a fragmented legacy estate, because every model then inherits the data quality problems underneath it. Start the pilot early, but let the platform catch up before you generalize.
The choice follows three questions: where is your data legally allowed to reside, what does the workload profile actually require, and what tooling do your teams already operate. AWS and Azure European regions cover most enterprise cases, and we pick between them on workload fit rather than preference. Sovereign European hosting becomes the right answer when public sector requirements, sector regulation or strategic independence rule out hyperscaler dependency, particularly for AI workloads processing sensitive documents. Because we engineer for portability, with infrastructure as code and open standards, the decision is revisable later rather than a one-way door.
A first production use case typically lands within three to six months: a bounded set of sources consolidated, quality rules in place, and one team answering real questions from the platform. Full consolidation takes longer and depends mostly on the number and state of your sources; an estate of 90+ databases takes more than a year to absorb completely. We deliberately phase the work so value arrives early, because a data lake that stays invisible for 18 months loses its sponsors before it loses its budget. Each phase adds sources to a platform already in daily use rather than building toward a single distant launch.
As design constraints, settled before the first deployment rather than reviewed after it. For GDPR that means data residency in European regions or on sovereign hosting, minimization built into pipelines, access controls and audit trails at the platform layer, and support for your DPIA process. For the AI Act it means classifying each use case by risk category, documenting models and training data so they can withstand scrutiny, and keeping humans in the loop where the regulation requires it. Where the requirements rule out hyperscaler AI services entirely, we train and run custom models on European infrastructure with no external API dependency.
That is the normal setup, and the handover is planned from the start rather than improvised at the end. Your engineers work inside the project, the infrastructure is managed as code so every environment is reproducible, and the architecture is documented end to end. By the time the platform is stable, your team operates it day to day, and we stay involved where it makes sense: new stages of the stack, model retraining, or capacity your team does not need to build in-house. The dependency you keep should be a choice, never a consequence of how the system was built.